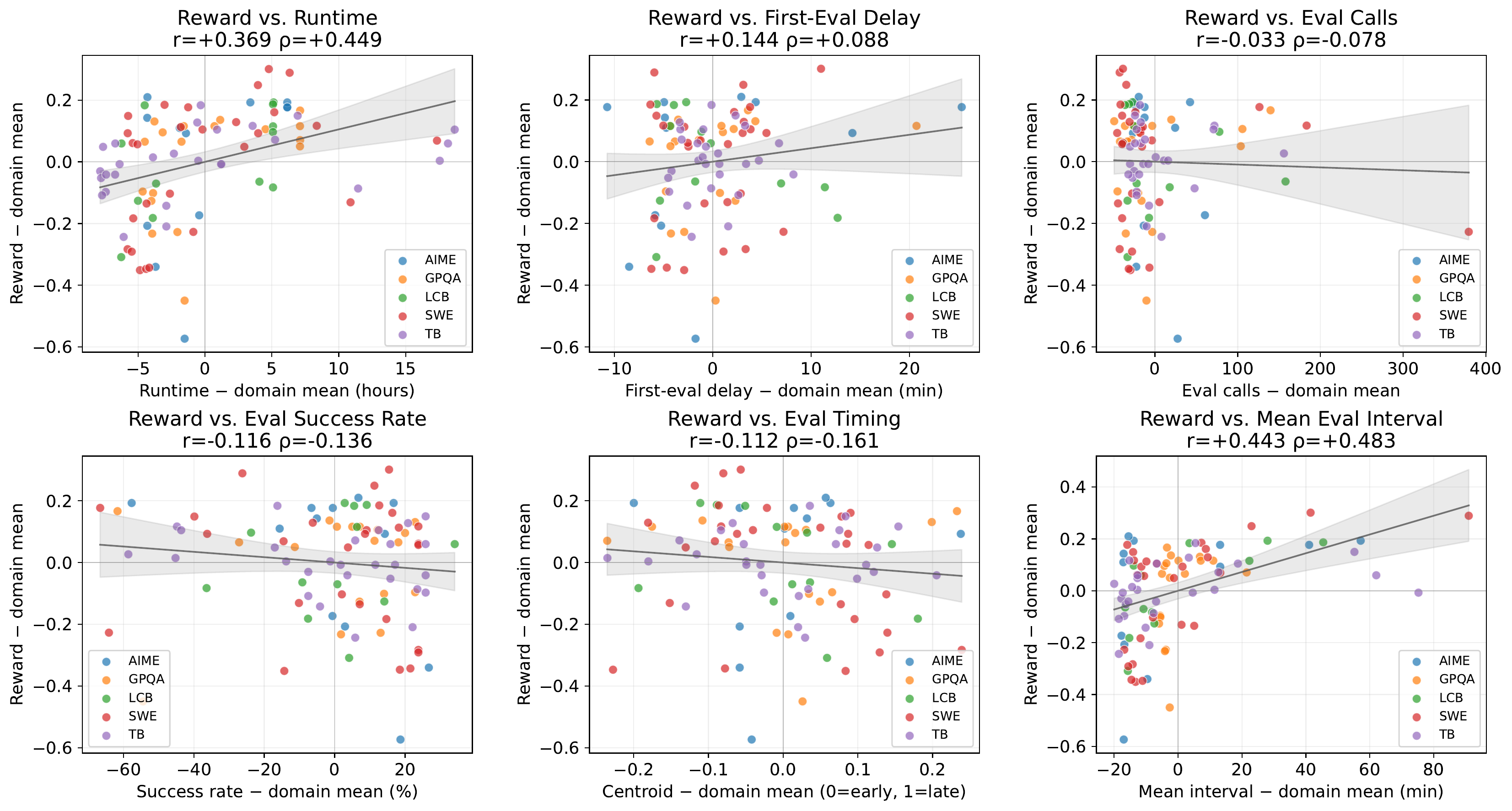
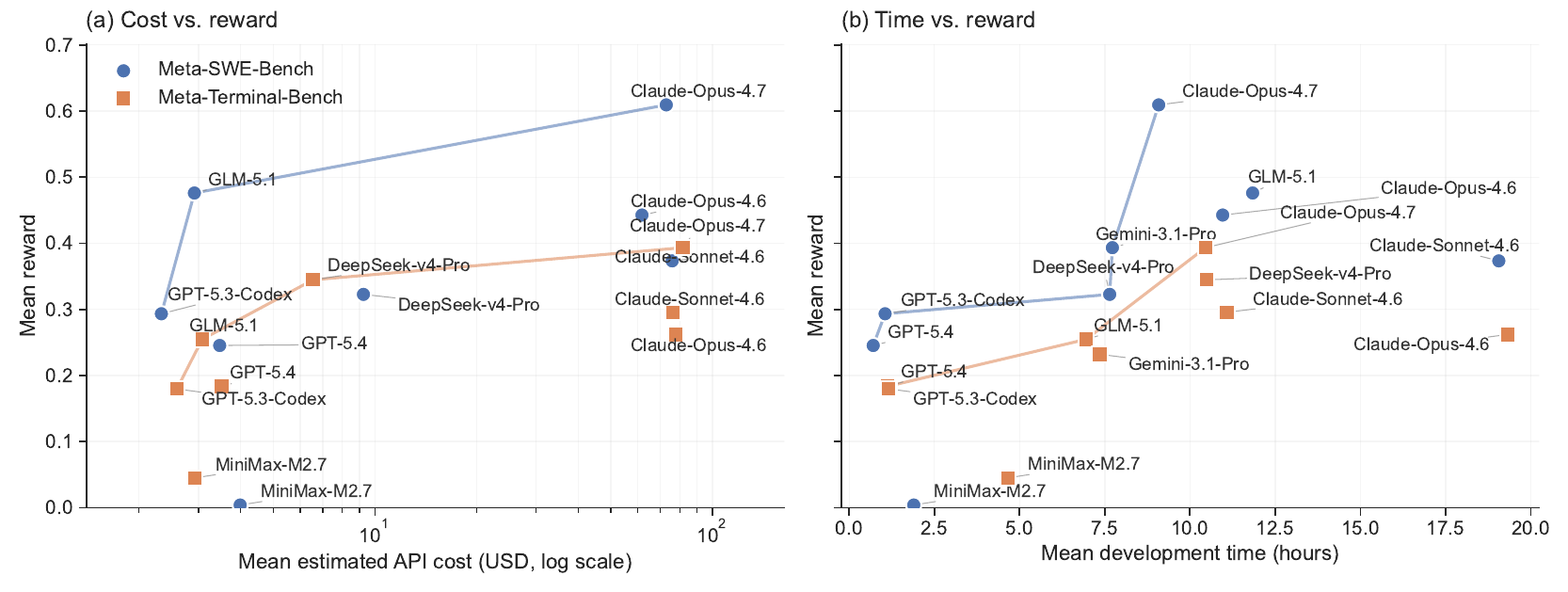
Evaluation protocol
Two phases, two containers, one trial.
A trial is a two-phase loop inside a dual-container architecture. The meta-agent never reaches the test split.
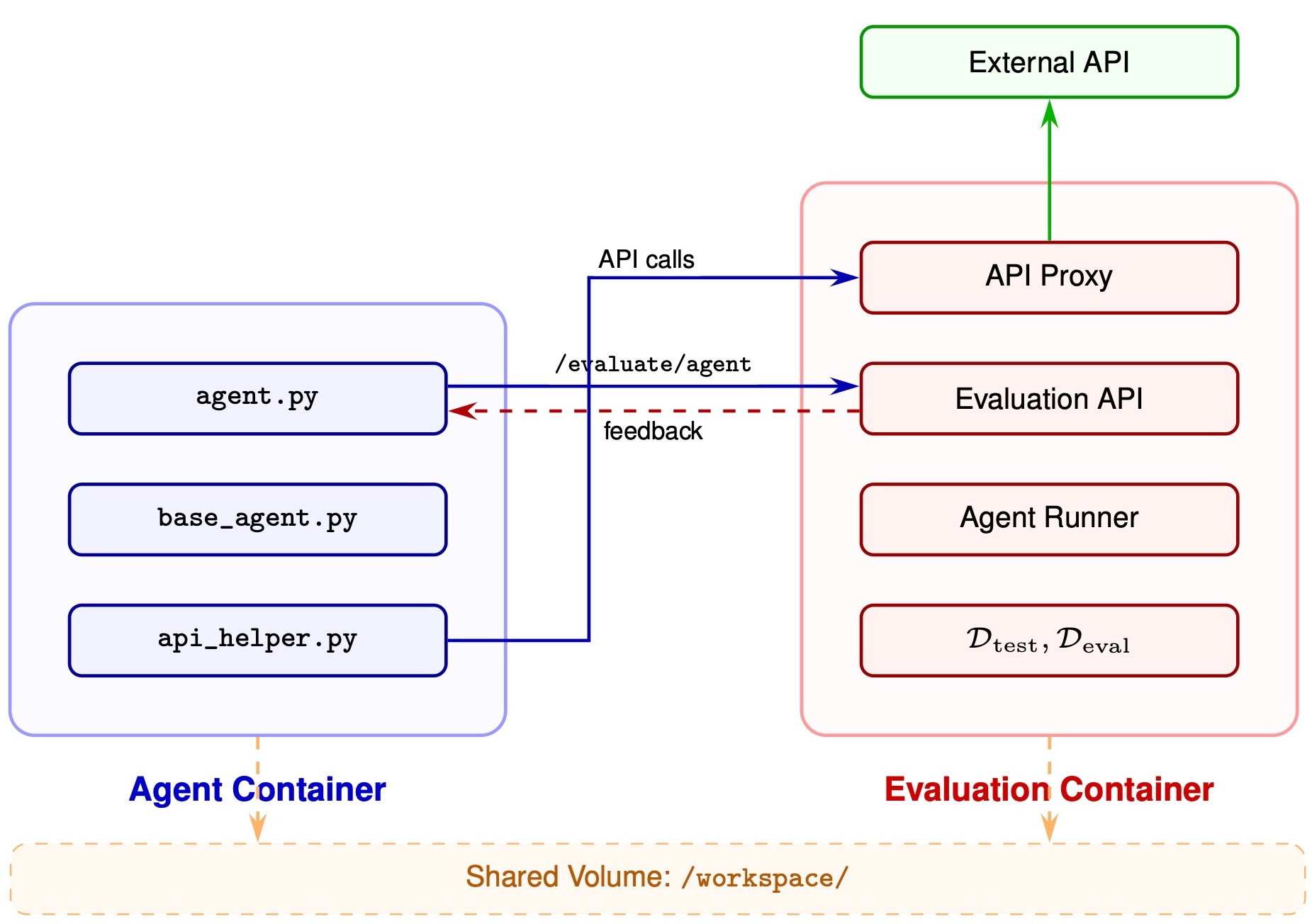
Development phase
The meta-agent reads the task, edits agent.py, calls the
dev-set evaluator, and iterates within
T_dev and R_api,dev.
Verification phase
When the budget expires, the static analyzer scans the workspace, the artifact runs on the held-out test set, predictions are graded, and the final reward is recorded.
Because Dtest is hidden during development, the meta-agent cannot solve this directly. It must rely on empirical feedback from the dev set to iteratively propose, evaluate, and refine — mirroring the trial-and-error cycle of a human developer.